Vision Representation From Textual
Vision Representation From Textual大多数的视觉特征表示都是通过有有监督的有标图像预训练得到的,最近有一种新方法是利用图像的caption信息对视觉特征进行监督学习。
Virtexpaper | code
Motivation
最近的文章很多都是在探索无标签自监督的对比学习方法对视觉表征进行提升,作者致力于用更少的图像学习更好的视觉表征。
作者利用语义密集的caption对图像进行监督,可以达到很好的效果,自监督的对比学习是用语义稀疏的信号使经过不同变换的图像具有相似的特征。
Contribution验证了自然语言能够对可迁移的视觉图像特征学习提供很好的监督,能够在用更少的图片的情况下学习到更好的表征能力
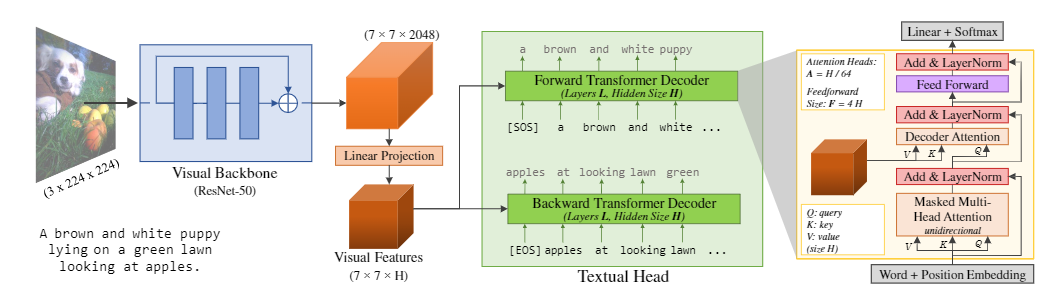
Method由visual backbone和textual head组成
在预训练过程中,language modeling部分任务是image caption,论文参考BERT的设计,并且考虑到计算量限制,没有采用MLM预训练任务。visual backbone部分,作者采用的是标准的REsNet-50网络,使用的特征为经过最后一层conv的 ...
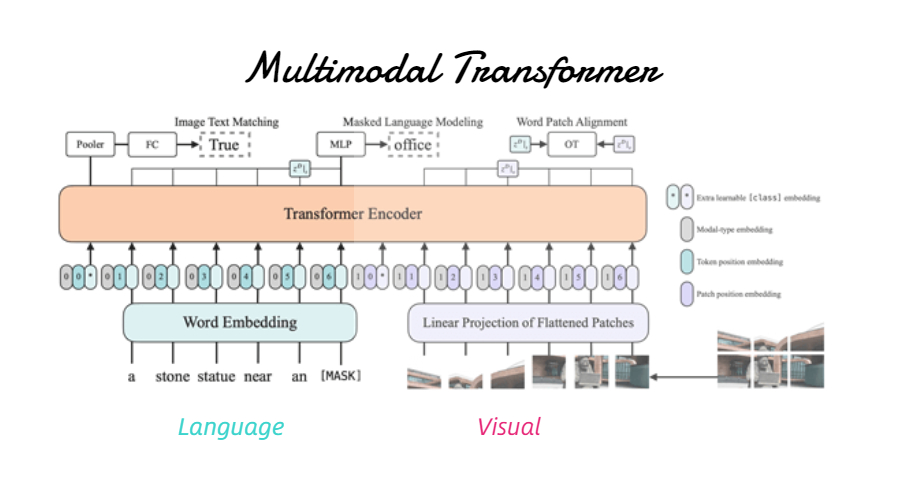
Multimodal-Transformer
Multimodal-TransformerVisual Embedding Schema
图片来自ViLT
Region Feature
利用faster rcnn提取bbox的region feature作为multimodel transformer的输入。
ViLBert|LXMERT|VL-BERT|VisualBert|Unicoder-VL|UNITER|VinVL
Grid Feature
直接利用CNN backbone提取出的grid feature
Pixel-Bert|CLIPBERT
Patch Projection
类似VIT将输入的图像分成多个patch直接输入transformer
image:ViLT
video:TimeSformer|ViViT|VTN
由于Region Feature方法对于视频数据不是很友好,主要介绍Grid Feature方法和Patch Projection方法
Grid FeaturePixel-Bertpixel-bert提出是为了解决目前Region Feature方法的一些问题,这些方法只能提取到图片的 ...
Knowledge Distillation
知识蒸馏是一种模型压缩常见方法,用于模型压缩指的是在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识”蒸馏出来,传递给参数量小、学习能力弱的网络。蒸馏可以提供student在one-shot label上学不到的soft label信息,这些里面包含了类别间信息,以及student小网络学不到而teacher网络可以学到的特征表示‘知识’,所以一般可以提高student网络的精度。
本文对一些KD方法的benchmark的论文进行一些方法总结。代码分析主要来自github。
Distilling the Knowledge in a Neural NetworkNIPS 2014 [https://arxiv.org/abs/1503.02531]
这篇论文是知识蒸馏的开山之作,简单来说,KD就是将一个大模型(Teacher)或者多个模型的ensemble学习到的知识迁移到更轻量的模型(Student)上继续学习,从而提高student的性能。
本文提出的方法是用大模型的类别概率(logits)作为”soft target” ...

DL面试知识点
【本文转载自Github,对其知识点进行补充】
深度学习神经网络中的Epoch、Iteration、Batchsize神经网络中epoch与iteration是不相等的
batchsize:中文翻译为批大小(批尺寸)。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
iteration:中文翻译为迭代,1个iteration等于使用batchsize个样本训练一次;一个迭代 = 一个正向通过+一个反向通过
epoch:迭代次数,1个epoch等于使用训练集中的全部样本训练一次;一个epoch = 所有训练样本的一个正向传递和一个反向传递
举个例子,训练集有1000个样本,batchsize=10,那么:训练完整个样本集需要:100次iteration,1次epoch。
参考资料
神经网络中的Epoch、Iteration、Batchsize
神经网络中epoch与iteration相等吗
反向传播(BP)
参考资料
一文搞懂反向传播算法
numpy实现简单的BP神经网络
CNN本质和优势局部卷积(提取局部特征)
权值共享(降低 ...
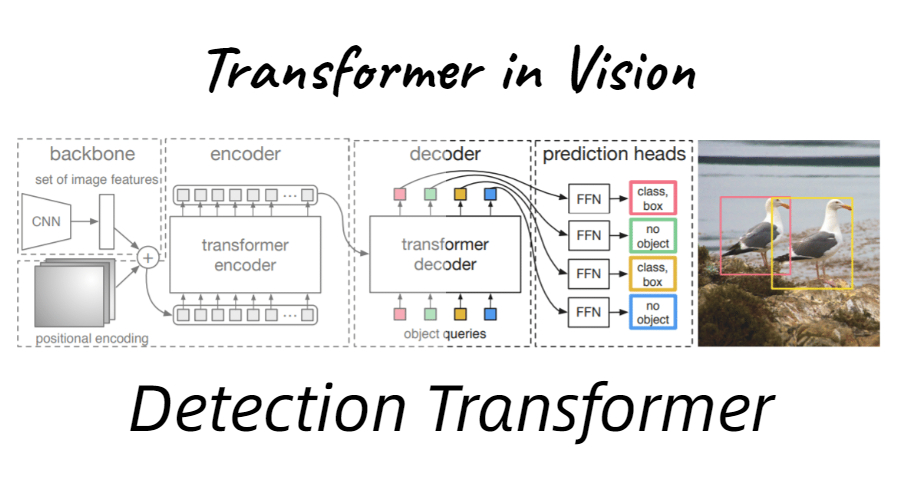
DETR-note
Transformer和AttentionTransformerTransformer本质上是一个Encoder-Decoder的结构
在paper中,encoder和decoder都由6个block组成,编码器的输出作为解码器的输入。
encoders每个block都是独立的单元,不会share weights。每个block又由以下的两部分组成(self-attention和FFN)
在decoder部分每个block也和encoder相似,只是在两层之间加了一个attention层(类似于seq2seq的attention机制,可以让decoder更加关注input相关的部分)。
编码器
编码器接受单词的词嵌入列表作为输入(列表中每个向量为512-d)。单词在通过self-attention层时会依赖单词之间的关系,但是在通过Feed Forward时没有这些依赖关系,可以并行进行。
self-attention类似于RNN中的隐藏层,self-attention的作用是将其他单词的信息融入到正在处理的单词中。
PS: ”The animal didn't cros ...

PolarMask-note
PolorMask:one-stage实例分割新思路前置知识FCOS FCOS是一个基于全卷积的one-stage检测网络,类似于语义分割针对每个像素进行预测。FCOS是anchor free,proposal free的检测器,可以减少大量的内存计算以及内存占用,并且不需要调优设计anchor和proposal的超参数。事实上这个anchor free方法还是有anchor的只不过不再是box形式,而是用点作为anchor,既减少了anchor数量又取消了超参。此外文章还提出了一个思路:将检测问题可以统一到其他FCN_solvable问题,可以简单的重用其他任务的idea。
网络结构图如下:
可以从图中看出网络结构中也运用了FPN的结构但是没有使用backbone的所有卷积层,但考虑了多尺度的问题直接加入了P5的下采样P6/P7。最后的损失函数也分为三个分支,classification、regression(不同于boxes,回归的4D向量为[l, r, t, b]代表每个像素点向四周的延伸)、centerness。
文章还解决了重叠区域问 ...

Retinanet&focal-loss
RetinaNet只是原来FPN网络与FCN网络的组合应用,因此在目标网络检测框架上它并无特别亮眼创新。文章中最大的创新来自于Focal loss的提出及在单阶段目标检测网络RetinaNet(实质为Resnet + FPN + FCN)的成功应用。Focal loss是一种改进了的交叉熵(cross-entropy, CE)loss,它通过在原有的CE loss上乘了个使易检测目标对模型训练贡献削弱的指数式,从而使得Focal loss成功地解决了在目标检测时,正负样本区域极不平衡而目标检测loss易被大批量负样本所左右的问题。此问题是单阶段目标检测框架(如SSD/Yolo系列)与双阶段目标检测框架(如Faster-RCNN/R-FCN等)accuracy gap的最大原因。
Focal LossFocal Loss主要解决的是类别不平衡问题,常规的单阶段目标检测网络像SSD一般在模型训练时会先大密度地在模型终端的系列feature maps上生成出10,000甚至100,0000个目标候选区域。然后再分别对这些候选区域进行分类与位置回归识别。而在这些生成的数万个候选区域中,绝大多 ...
FPN-note
FPN(Feature Pyramid Networks for Object Detection)FPN解决的主要问题是检测算法在处理多尺度变化问题时的不足以及对小物体检测不友好的问题。传统的方法是构造图像特征金字塔,但是计算量很大,FPN通过独特的构造避免了计算量过高的问题,并且有良好的多尺度处理性能。
图a为传统的多尺度特征提取方法,计算量极大。
图b为单一特征的检测系统,有很大的局限性。
图c为网络多层次结构提取特征,但是存在底层语义较弱的问题。
图d为FPN金字塔特征提取,能够让各个不同尺度的特征都拥有较强的语义信息。
FPN算法 FPN包含两个部分:第一部分是自底向上的过程,第二部分是自顶向下和侧向连接的融合过程。
自底向上过程 自底向上的过程和普通的CNN没有区别。现代的CNN网络一般都是按照特征图大小划分为不同的stage,每个stage之间特征图的尺度比例相差为2。在FPN中,每个stage对应了一个特征金字塔的级别(level),并且每个stage的最后一层特征被选为对应FPN中相应级别的特征。以ResNet为例,选取conv2、conv3、conv4、con ...
PSPNet-note
Pyramid Scene Parseing Network Note PSPNet 采用金字塔池化模块搭建的场景分析网络 , 基于语义分割的场景解析,其目的是赋予图像中每个像素一个类别标签。
1 PSPNet介绍由于传统的FCN存在缺陷:
不匹配上下文关系, FCN将水中的“boat”预测为“car” 。
类别混淆,将摩天大楼一部分识别成了其他。
不显著的类别难以预测,可能会忽略小的东西。
基于对FCN的透彻分析,作者提出了能够获取全局场景的深度网络PSPNet,可以融合局部特征和全局特征,有较好的效果。
1.1 Pyramid Pooling Module(金字塔池化模块) 金字塔池化模块Pyramid Pooling Module由一组不同尺度的池化块组成
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1X1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终conc ...
FCN note
FCN:Semantic Segmentation图像的语义分割,简言之就是对一张图片上的所有像素点进行分类
1 FCN介绍 与传统的CNN解决的分类与检测问题不同,语义分割是一个空间密集型的预测任务,是像素级别的,需要对图像上所有的像素进行分类。 由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
FCN是针对语义分割训练的的一个端到端的网络, 是处理语义分割问题的基本框架,后续算法其实都是在这个框架中改进而来。
1.1 卷积化 在一般的分类任务中在conv层之后一般会有全连接层,将二维的图像特征压缩为一维,可以训练输出一个标量,成为分类标签。这样做会失去部分的空间信息,不适用于分割的操作。
语义分割输出为分割图,信息是二维的,所以在进行网络构建的时候抛弃了全连接层而是采用了卷积层,叫做卷积化。
1.2 上采样(Upsampling)上采样与下采样相反,我们需要得到原图像的分割图就需要将缩 ...