RetinaNet只是原来FPN网络与FCN网络的组合应用,因此在目标网络检测框架上它并无特别亮眼创新。文章中最大的创新来自于Focal loss的提出及在单阶段目标检测网络RetinaNet(实质为Resnet + FPN + FCN)的成功应用。Focal loss是一种改进了的交叉熵(cross-entropy, CE)loss,它通过在原有的CE loss上乘了个使易检测目标对模型训练贡献削弱的指数式,从而使得Focal loss成功地解决了在目标检测时,正负样本区域极不平衡而目标检测loss易被大批量负样本所左右的问题。此问题是单阶段目标检测框架(如SSD/Yolo系列)与双阶段目标检测框架(如Faster-RCNN/R-FCN等)accuracy gap的最大原因。
Focal Loss
Focal Loss主要解决的是类别不平衡问题,常规的单阶段目标检测网络像SSD一般在模型训练时会先大密度地在模型终端的系列feature maps上生成出10,000甚至100,0000个目标候选区域。然后再分别对这些候选区域进行分类与位置回归识别。而在这些生成的数万个候选区域中,绝大多数都是不包含待检测目标的图片背景,这样就造成了机器学习中经典的训练样本正负不平衡的问题。它往往会造成最终算出的training loss为占绝对多数但包含信息量却很少的负样本所支配,少样正样本提供的关键信息却不能在一般所用的training loss中发挥正常作用,从而无法得出一个能对模型训练提供正确指导的loss。
Focal Loss定义
$FL(p_t)=-\alpha_t(1-p_t)^rlog(p_t)$
下图为focal loss与常规CE loss的对比。从中,我们易看出focal loss所加的指数式系数可对正负样本对loss的贡献自动调节。当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。不过在此focus loss计算当中,我们引入了一个新的hyper parameter即γ。一般来说新参数的引入,往往会伴随着模型使用难度的增加。在本文中,作者有试者对其进行调节,线性搜索后得出将γ设为2时,模型检测效果最好。
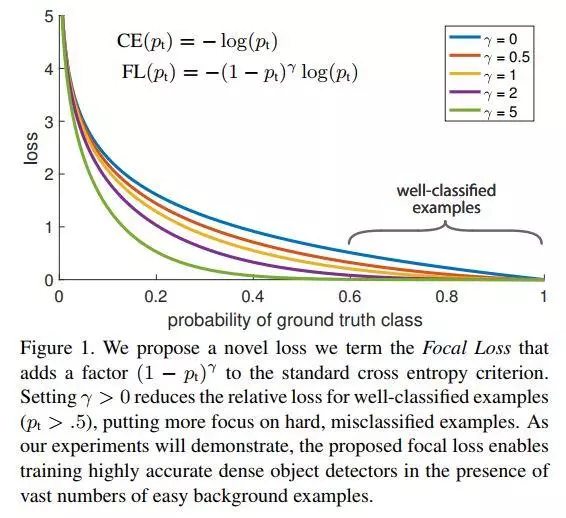
在最终所用的focal loss上,作者还引入了α系数,它能够使得focal loss对不同类别更加平衡。实验表明它会比原始的focal loss效果更好。
Focal loss还很大程度上避免了正负样本不平衡带来的模型初始化问题。
代码实现
1 |
Retinanet
RetinaNet本质上是Resnet + FPN + 两个FCN子网络。
RetinaNet检测框架
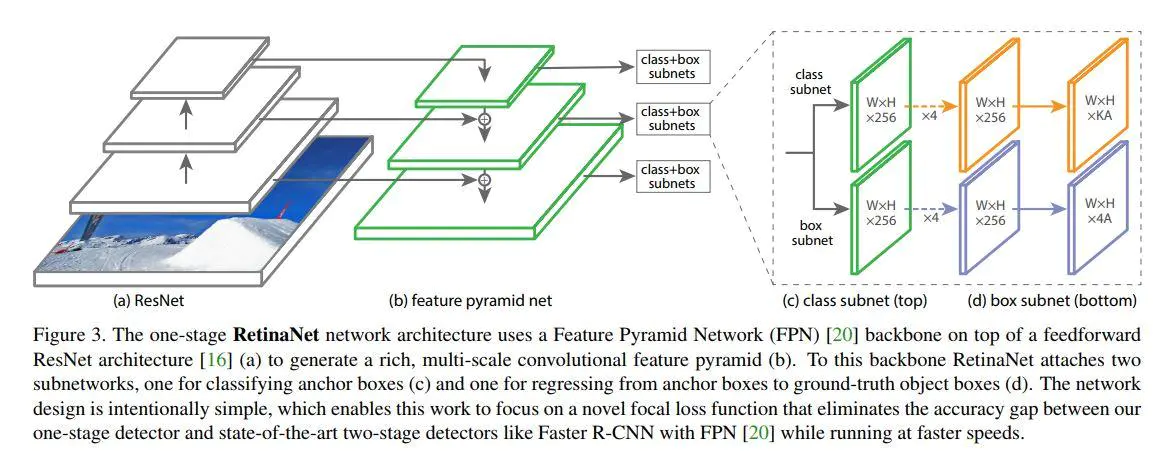
一般主干网络可选用任一有效的特征提取网络如vgg16或resnet系列,此处作者分别尝试了resnet-50与resnet-101。而FPN则是对resnet-50里面自动形成的多尺度特征进行了强化利用,从而得到了表达力更强、包含多尺度目标区域信息的feature maps集合。最后在FPN所吐出的feature maps集合上,分别使用了两个FCN子网络(它们有着相同的网络结构却各自独立,并不share参数)用来完成目标框类别分类与位置回归任务。