Transformer和Attention
Transformer
Transformer本质上是一个Encoder-Decoder的结构
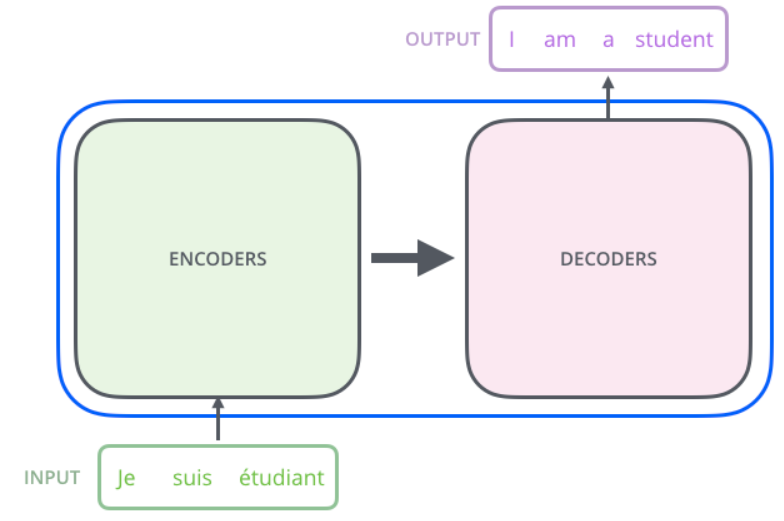
在paper中,encoder和decoder都由6个block组成,编码器的输出作为解码器的输入。
encoders每个block都是独立的单元,不会share weights。每个block又由以下的两部分组成(self-attention和FFN)
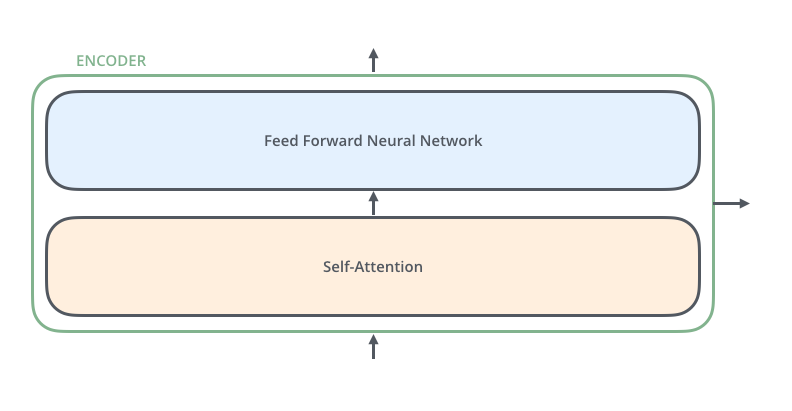
在decoder部分每个block也和encoder相似,只是在两层之间加了一个attention层(类似于seq2seq的attention机制,可以让decoder更加关注input相关的部分)。
编码器
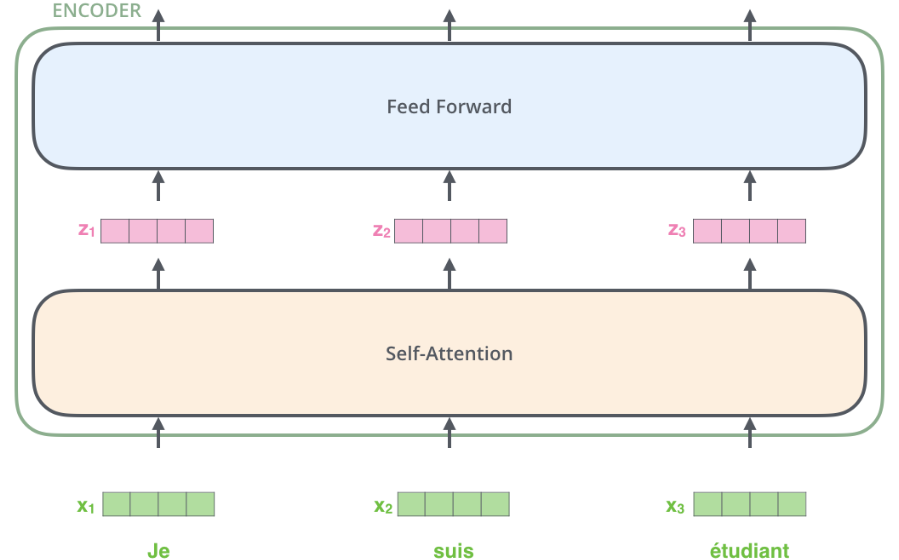
编码器接受单词的词嵌入列表作为输入(列表中每个向量为512-d)。单词在通过self-attention层时会依赖单词之间的关系,但是在通过Feed Forward时没有这些依赖关系,可以并行进行。
self-attention
类似于RNN中的隐藏层,self-attention的作用是将其他单词的信息融入到正在处理的单词中。
PS: ”The animal didn't cross the street because it was too tired” 在处理it时会将前文the animal等信息加到it中。
三个向量
self-attention的第一步就是从输入的词嵌入向量列表生成三个向量(64-d)
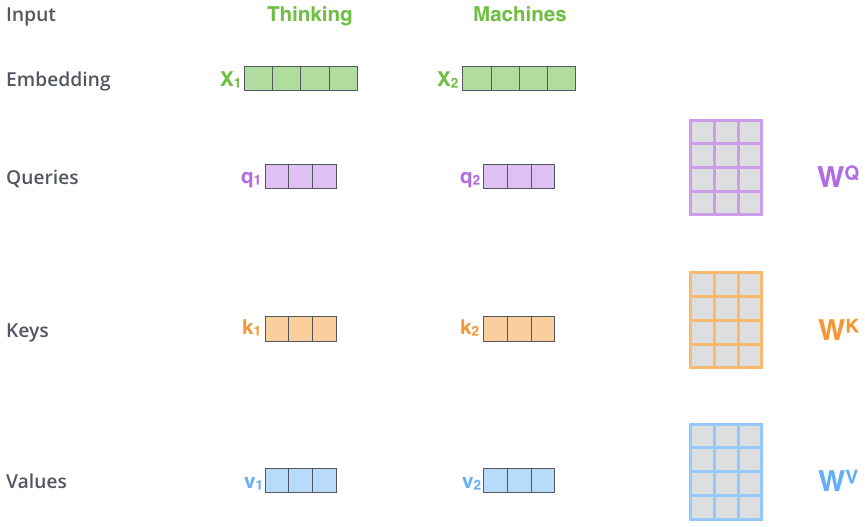
query vector:与其他单词的key vector相乘计算得分
key vector:与其他单词query vector相乘代表对其他单词在语义上的影响
value vector:
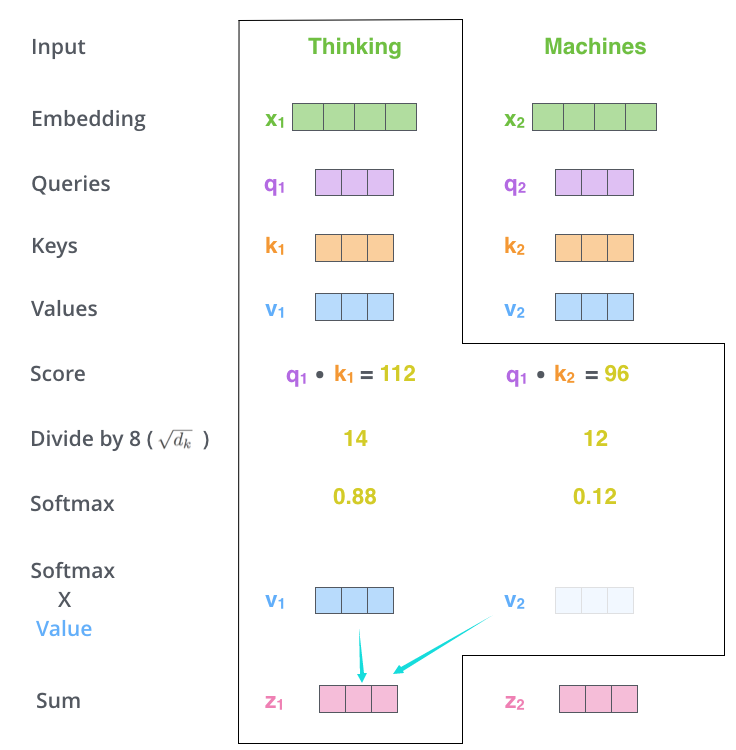
第二步是对输入的单词进行得分计算,得分决定了这个词在句子中有多重视其他部分。
得分的计算是由其他单词的key vector和该单词的query vector进行点积计算。
第三步是对每个得分除以$\sqrt{d_k}$然后进行softmax可以得出每个位置的单词对该位置的贡献。
第四步是将每个单词的value vector与求出来的softmax权重相乘,可以关注语义上联系很强的单词。
第五步是将所有带权重的value vector进行求和,当作self-attention的输出。
在实际的运算中是以矩阵来进行运算的。
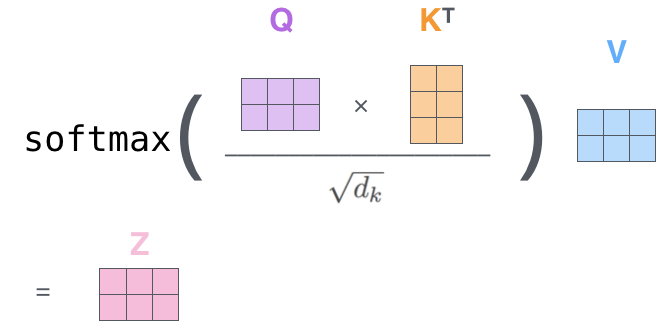
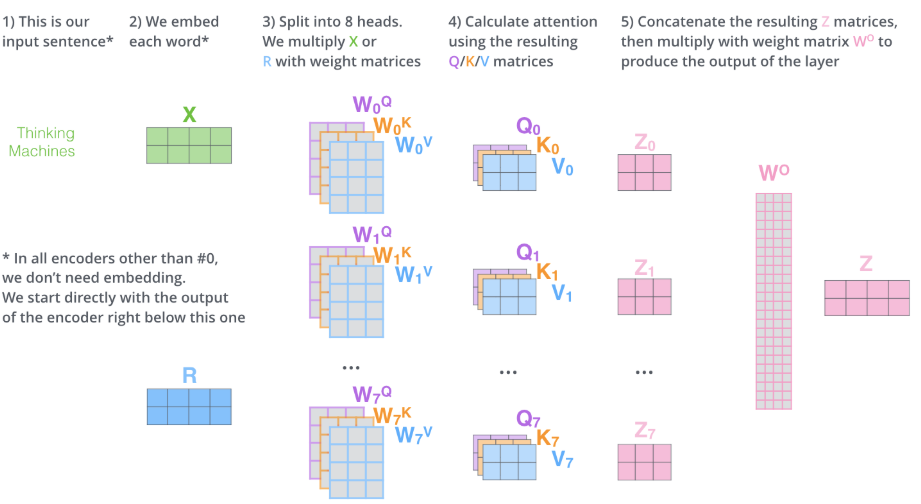
multi-head机制
- 多头注意力扩展了模型专注于不同位置的能力
- 可以将每个词嵌入投射到不同的子空间
n个注意力头会产生n个z输出,通过$W^0$与拼接好的输出进行相乘得到最后融合多个注意力头的Z

self-attention的总体计算过程
Position Encoding
在词嵌入中,将每个单词的位置编码(向量)加入到嵌入向量中,描述单词的输入顺序。
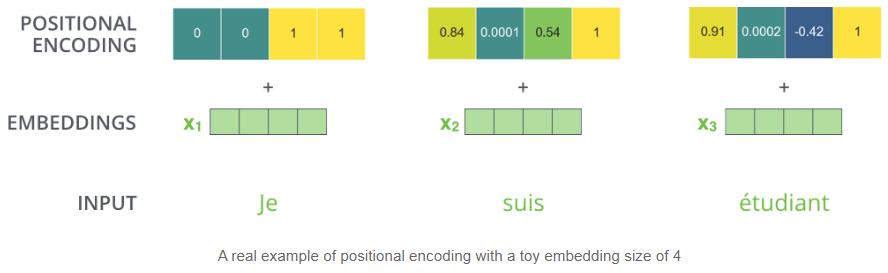
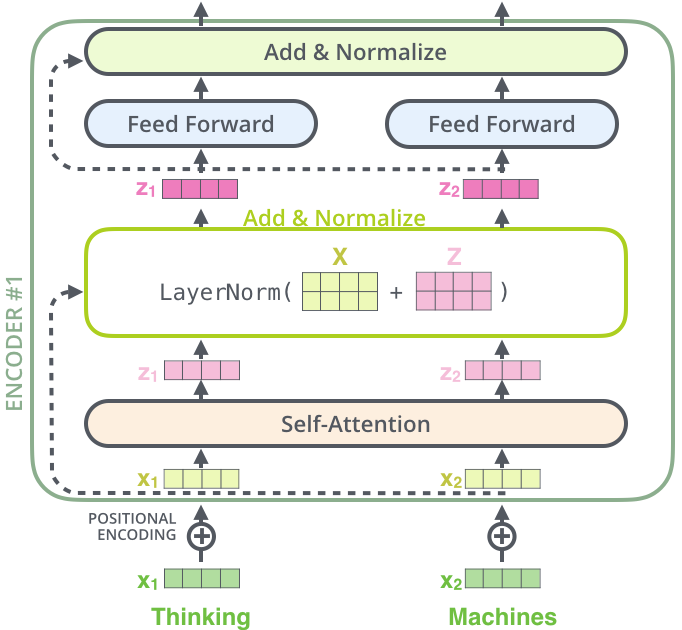
(Positional Embedding左半部分通过正弦函数求出,右半部分通过余弦函数求出)
Residuals
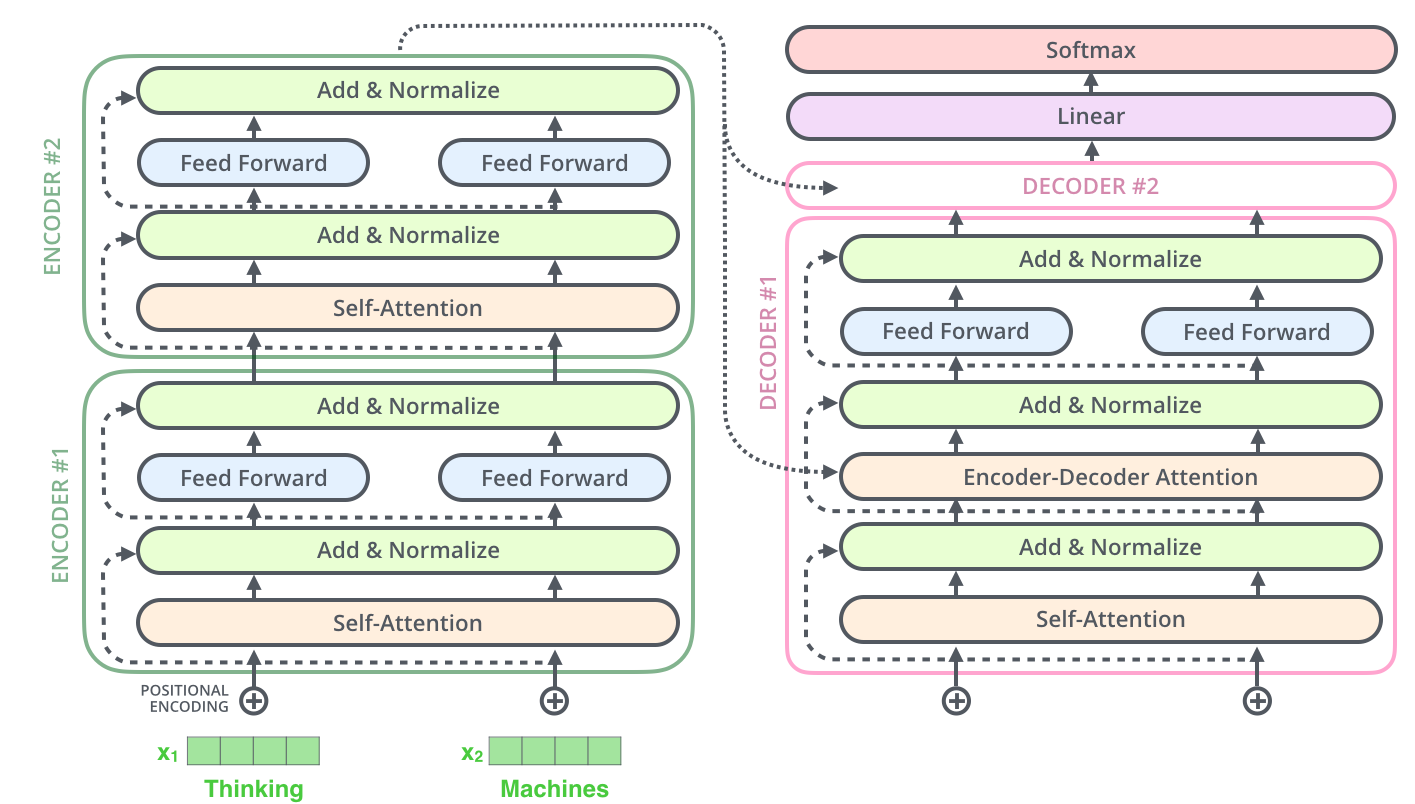
解码器
![]()
编码器通过处理输入序列开启工作。顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集 。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适 。
这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它下面的层来创造查询矩阵,并且从编码器的输出中取得键/值矩阵。
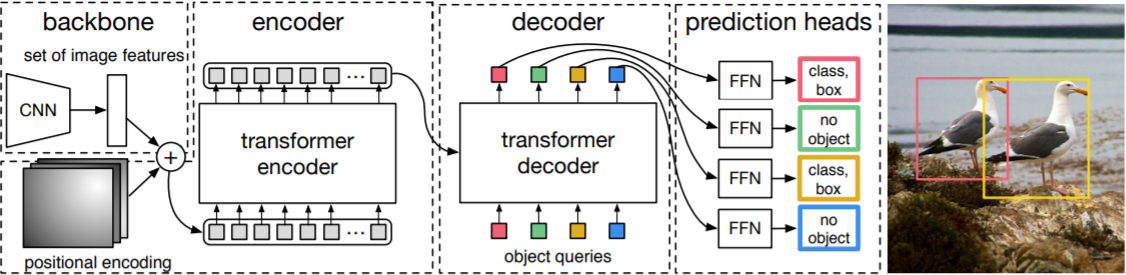
整体结构
DETR
二分图匹配损失函数(bipartite matiching loss)
图片经过CNN提取特征输入Transformer模型,输出N个固定prediction box(class, bbox)格式。GT的bbox也以(class,bbox)的形式存在,并且补齐N个$(\emptyset,*)$ bbox。
通过最佳匹配算法(匈牙利算法)来确定GT的最佳匹配框,然后可以计算损失函数。
将输出的bbox与GT的bbox对应起来,寻找一个最佳的对应关系,使得loss最小。(这样做的好处是可以将多个输出相同object的框选择一个最优的输出bbox与GT标注框对应,迫使模型学习输出更多不同object的bbox,并且匈牙利算法会对预测的object数大于GT的object数进行惩罚)
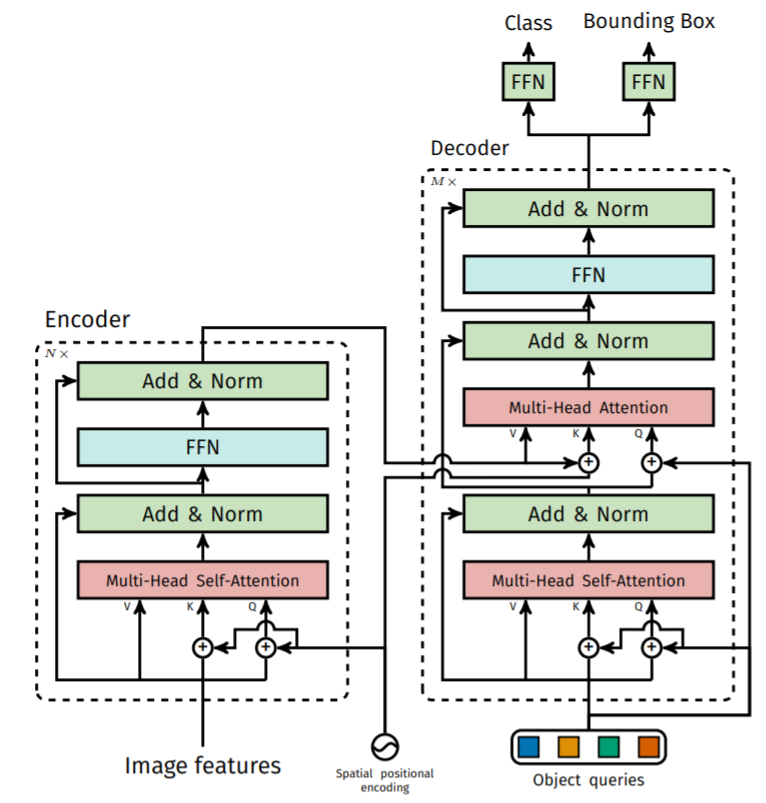
DETR结构
将图像经过CNN提取的特征与object的位置positional encoding结合送入transformer encoder中。
(由于transformer只接受序列化输入,所以将(C,H,W) flatten 得到(C, HXW)的序列化特征)
将encoder的输出特征传入decoder(相当于一个特征映射的过程,encoder能够学习更多的其他位置的特征),decoder的输入是object queries,object queries首先是n个随机变量,经过decoder融合encoder输出的图像信息得出n个合适的bbox输出(n个object queries可以当作n个不同的人从n个不同的角度对图像进行观测,注意图像不同的地方,是需要学习的)
具体结构
实现代码
pytorch
1 | import torch |

